
Where the Profits Live: A Map of the MCP Layer
The scarce layer captures the value. When that scarcity dissolves, the profits migrate. It’s happening in AI now. This is the map.
Perspective
~15 min read
The migration
A quiet pattern shows up every time a new technology stack matures. The work that used to require scarce skills becomes broadly available, and the value moves to wherever scarcity has shifted to. In the early web, building a site was hard, so the people who could build sites captured the margin. Then, content management systems made building trivial, and the margin moved to whoever could ship, hosts, CDNs, and cloud platforms. Cloud commoditized shipping, and the margin moved again to whoever could distribute. App stores, marketplaces, and the platforms that decided which products users actually saw became where the money lived.
The same migration is happening now, on a much faster clock, inside the AI stack.
Building software is being commoditized by AI itself. Anyone with a prompt can produce working code, working pages, and working interfaces. Cloud absorbed shipping a decade ago. The scarce layer that remains is reach; the ability to become the thing the user — or increasingly the orchestrating AI — actually encounters when help is needed. In the agentic stack, that gap has a specific shape, and it is becoming visible faster than most product teams are pricing it.
That interface has two sides — AI systems producing rich interactive output (HTML, dashboards, charts, forms) and the surfaces that can actually render it for a user, connected by an emerging protocol called the Model Context Protocol (MCP).
What this does to the producer-consumer map is significant. The consumer side stops being a fixed list of apps that happen to render HTML, and becomes a list of apps that can be reached by any MCP-aware tool, regardless of who built it. A rendering surface used to be a UI feature. With MCP, it becomes a distribution surface. Build your tool as an MCP server, and the question of which surfaces can render your output collapses into the question of which surfaces your users already use. Those become the same question.
This piece is a map of where the gap sits. We will look at three corners of one triangle: the agents producing rich output, the surfaces rendering it, and the protocol that connects them. Then we will draw the strategic implications that we think most teams in the space have yet to absorb.
The producer side is a flood
A note on what we mean by rich output. We mean anything an AI generates that a human is meant to interact with, rather than just read. Interactive web pages, dashboards, forms, charts, embedded mini-apps, editable documents, runnable code, generated images, and structured data that becomes UI on arrival. HTML is the most general example and the most useful one to anchor on, so it will do a lot of the work in this piece. The pattern we will describe holds for the rest.
Consider the producer side first. So many AI systems now emit rich output that any inventory dates within weeks of publication.
A first group is the general-purpose assistants: Claude, ChatGPT, Gemini, and Mistral Le Chat. These will write, render, and iterate on HTML, CSS, and JavaScript directly inside the chat surface, and most of them now produce images, charts, and editable documents alongside. A second group is the coding and deployment agents: v0, Bolt.new, Replit Agent, Cursor, Windsurf, GitHub Copilot. These turn natural language into running web apps with live preview, often without the user ever touching code. A third group is the dedicated agent platforms: Taskade Genesis, MindStudio, and Beam AI. For these, rich output is a first-class deliverable rather than a side effect. A fourth group is the design-to-code tools, Anima and its peers, that compile Figma and Sketch files into production HTML and React.
The taxonomy will keep getting longer. The takeaway is already becoming clear. Producing rich output is rapidly moving from differentiated capability toward infrastructure. The quality, reliability, and orchestration still vary meaningfully between systems, but the ability to generate working interfaces, charts, documents, and applications is no longer rare. What used to set products apart is becoming baseline. As generation becomes broadly accessible, the strategic weight shifts toward where outputs are rendered, trusted, governed, and reached.
If producing rich output is the answer, the question is uninteresting. The interesting question is what happens to the output once it exists.
The consumer side is gated
Here is where the map gets strategic. Not every AI surface can render rich output when it receives some. The ability to take an interactive artifact and put it in front of a user, what Claude calls Artifacts and what ChatGPT, Gemini, and Le Chat call Canvas, is not universal. The pattern of who has it and who does not is also not random.
We pulled this together as a working table. It is a partial list, current to mid-2026, focused on HTML rendering because HTML is the most general carrier. The same shape holds for documents, embedded charts, generated images, and runnable code, with each modality drawing a slightly different version of the same map.
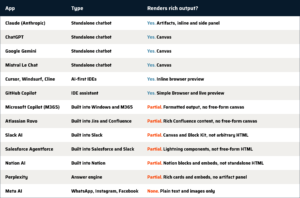
The shape that jumps out is which kinds of apps render fully and which do not. The standalone assistants, the places where a user goes specifically to interact with an AI, almost all have a first-class canvas. The AI-first code editors — Cursor, Windsurf, Cline — render too. Their users are mostly developers and developer-adjacent technical staff, and code editors have shown live previews of HTML for years. AI-generated HTML inherits the convention. The category that is consistently “partial” is the one that matters most for enterprise distribution: Copilot, Rovo, Slack, Salesforce, and Notion. These are the places users already live, the surfaces they open out of habit. Rendering inside an enterprise platform cannot be free-form because the platform has to protect its data model, its security posture, and its UI grammar. So the rich output gets compressed into the platform’s native vocabulary on the way through.
That compression is the bottleneck. The producer side is generating an unlimited supply of rich agent output. The consumer side decides whether that output reaches a human, in what form, and inside whose product. In a stack where producing is free and consuming is gated, value gathers on the gated side. That rule has held in every prior migration, and we have no reason to expect this one to behave differently.
A buyer at a major medical device manufacturer described what “partial” feels like from the inside, talking about her team’s existing workflow:
“One of the challenges was that we don’t want to export our documentation and analyze it in a different platform. Everything moving forward is going to be in Jira and Confluence… people are basically using Rovo because there’s a tool in there where you can individually input requirements and it gives you feedback — I’m not sure what criteria it’s using.”
That is what compression sounds like from inside the workflow. The output reaches her on the surface she lives in. The criteria that would make it trustworthy do not.
Two recent moves show this surface-to-surface flow becoming concrete. Figma has opened its canvas to agents, letting AI design directly inside Figma rather than producing output that a designer has to paste in. Canva announced a partnership with Anthropic that lets Claude Artifacts be brought into Canva and edited as native design elements. Surfaces are quietly becoming pass-throughs for each other, and the question of which surface renders which kind of output is no longer an abstract one.
MCP is the wire
As we previewed at the start, MCP is what collapses the consumer-side gating into a distribution opportunity. Here’s how that actually works.
Until recently, the producer-consumer mismatch was a frontend problem. You built your tool, and if you wanted it inside someone else’s assistant or IDE, you wrote a custom integration for each surface. One for Slack, one for Teams, one for Salesforce, each with its own SDK and its own update cycle. Most teams gave up after two or three integrations. The economics of integrations-as-a-strategy never worked for anyone except the biggest platforms.
MCP changes the shape of that problem. MCP is, in the simplest framing, a USB-C port for AI applications. A tool exposes itself once as an MCP server. Any AI app that speaks MCP, including the assistants, the IDEs, the enterprise surfaces, and increasingly the chat platforms, can plug in and call it. The user asks the AI a question. The AI decides whether to call the tool. The tool answers. The AI uses the answer in its response. The user never leaves the surface they were already in.
A colleague captured the user-level version of this in a recent customer conversation:
“The idea is you make these connectors, and if you’re in a Copilot or ChatGPT or Claude, whatever tool you’re using, it has these connectors. So rather than having to copy a document and paste it in for context, you can say, go look at this file on my hard drive.”
That is the architecture as it reaches the user. The file does not need to leave its home. The user does not need to leave the assistant. The MCP server is the wire that carries the question and the answer between them.
MCP is thin by design. It does not solve identity, billing, permissions, governance, or trust on its own, and many of the operational questions around enterprise-scale MCP adoption are still unsettled. But as the wire that turns rendering surfaces into addressable distribution, it is already reshaping how AI systems connect to specialist tools. Adoption is moving quickly enough that the strategic implications are arriving before the standards fully stabilize. A majority share of the apps in the consumer-side table now support MCP as a client, a server, or both.
The how-to genre is forming quickly around this moment (a representative example). What is mostly absent from that genre is the question of which surfaces a specialist’s MCP server should be most reachable from. That is the strategic question our map is trying to answer.
What the map implies
Four patterns fall out of this map. These are shapes that the map is already drawn in, observations rather than forecasts.
First, horizontal AI will absorb generic capabilities by default. Anything a foundation model can do well enough on its own, including summarizing, translating, restructuring, and drafting, will be absorbed into the assistants. A product whose value proposition is “we do that thing the AI already does, with our brand on it” will face steady pressure from horizontal capability over time, and the room to hold ground there is narrowing.
Second, vertical specialists capture value by being callable. The vertical play is to become the credible system a horizontal AI reaches for when the question becomes serious enough, accurate enough, auditable enough, deterministic enough, or regulated enough that general capability alone is insufficient. Horizontal AI is optimized for fluency and breadth. The specialist’s strength is the property fluency cannot guarantee: repeatability, traceability, and defensible reasoning under constraint — the property that a specialist returns the same answer for the same input, with a record of how it got there. The user does not necessarily need to know the specialist is there. The orchestrating AI does. As more systems become reachable through shared protocols, invocation itself becomes a distribution channel in its own right.
We heard a senior engineer at a Fortune-100 industrial customer describe his own roadmap in exactly these terms:
“Some of that can be done with things like model context protocol and other elements. So we can ping the requirements thing, and then we can ping something else and do our analysis of completeness.”
The phrase “we can ping the requirements thing” is the buyer-side version of this architecture. Specialists become things that get pinged. That is the position to build for.
Third, the rendering surface is a strategic asset that very few people are pricing correctly. The surfaces with first-class canvas, Claude, ChatGPT, Gemini, and Le Chat, are usually discussed as products. They are also distribution channels. A specialist that produces rich interactive output reaches its full ceiling inside a canvas surface and gets compressed inside a partial one. The surface you can render in determines how much of your product the user actually receives.
Fourth, incumbents that already own distribution in a vertical will move to commoditize the tier below them. This is a familiar play. Vertical platforms that have spent a decade owning a workflow will use AI to absorb the specialist tools that sit inside that workflow, because the alternative is watching MCP-connected specialists reach their users without going through them.
This is already in motion. A buyer at a defense electronics manufacturer described his team’s reasoning plainly:
“[Two of the major incumbents] are creating their own capability to do the same kinds of things. And so why wouldn’t we just use those capabilities?”
A buyer at a global metals and mining company put the same observation more bluntly:
“Some of the product space that [the specialist tool] was filling for us, some of it can be done by a generic AI solution.”
These are not skeptics. They are customers in motion, asking the next obvious question.
But protocol-level reach does not automatically eliminate platform power. Once specialists become callable, the next control point becomes discoverability, which tools get surfaced, trusted, prioritized, or invoked by default inside the orchestrating AI. We expect incumbents to compete aggressively for that control point over the coming wave of adoption.
That matters because specialists reachable only through the incumbent’s surface remain the most exposed. Specialists the buyer’s AI can call independently and have more room to write a different ending. We are already hearing customers ask for exactly that, sometimes by protocol name. The category is moving quickly enough that we hold these patterns loosely; the shape is clear, the timing less so.
Where that leaves us
We work on requirements quality at QRA. Engineering requirements are, almost by definition, the kind of vertical depth that should not be absorbed into horizontal AI. The cost of a wrong answer is too high, the audit trail matters, and the standards are specific.
The architecture that fits this kind of work has elements we have been calling out for some time, and that no one else in our category is naming yet. Scribes generate and rephrase. A gavel scores AI outputs against the standards the program will be audited against, and records the chain of evidence behind every decision. Horizontal assistants are scribes by default. Without a gavel beside them, an engineer is left manually re-checking dozens of company rules and industry best practices — like the forty INCOSE rules — every time the AI returns an answer. And neither the scribe nor the gavel can do its work without the foundation they both sit on, the requirements intelligence layer. This architecture and the elements within it are named and argued in The Wrong Question, and its cost in regulated engineering is traced in The Hidden AI Tax in Regulated Engineering.
The fourth pattern above is the one most active in our category. There are incumbent platforms that already own distribution in requirements management, and they are running the absorption play. The answer the map points to is the work we are building toward: MCP distribution that lets the buyer’s AI reach the requirements intelligence layer directly, on the buyer’s surface, without requiring the workflow platform itself to mediate every interaction.
Others are drawing adjacent maps. CB Insights’ AI agent predictions for 2026 track where money, hiring, and M&A flow as agents move from prototype to production. Epsilla’s analysis of the open-source agent stack argues the moat keeps moving up the stack toward memory and orchestration. Both work in the same shape we are. Our map covers different ground, not the infrastructure that makes agents production-ready, but the vertical-specialist plays that decide whose expertise the agent calls when the answer has to be defensible, auditable, or signed for.
A companion piece accompanies this one. It looks at what changes at the use-case level when a purpose-built tool works alongside a horizontal assistant rather than against it; what “best of both worlds” actually looks like in a working day, and why teams who are happy with their current generic tooling should still care.
For now, the point of this piece is the map. If you are building, buying, or competing in the agentic stack, the producer-consumer-MCP triangle is the shape we think the next several years of the market will be drawn in. Producers are abundant. Consumers are gated. MCP is the wire. The profits live wherever those three meet.